模型介绍
与 GLM-4.5 相比,GLM-4.6 带来了几个关键改进:
- 更长的上下文窗口: 上下文窗口从 128K 扩展到 200K tokens,使模型能够处理更复杂的智能体任务。
- 更强的代码性能: 模型在代码基准测试中取得了更高的分数,并在实际应用中表现更佳,例如 Claude Code、Cline、Roo Code 和 Kilo Code,包括在生成视觉上更精美的前端页面方面的提升。
- 更先进的推理能力: GLM-4.6 在推理性能上有明显提升,并在推理过程中支持工具调用,从而带来更强的整体能力。
- 更强大的智能体: GLM-4.6 在工具使用和基于搜索的智能体方面表现更强,并能更高效地融入智能体框架。
- 更精细的写作: 更好地符合人类在风格和可读性上的偏好,并在角色扮演场景中表现得更加自然。
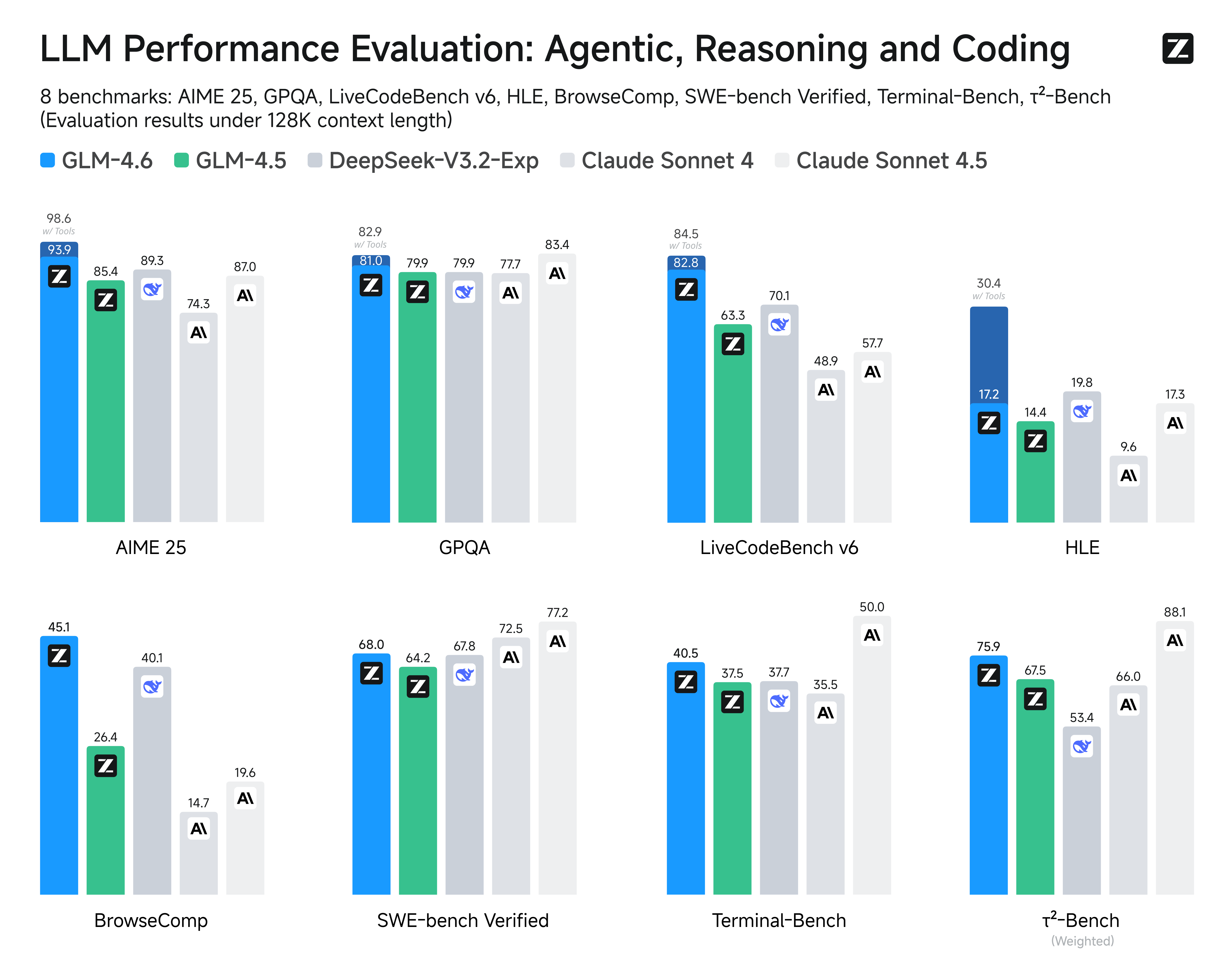
我们在涵盖智能体、推理和编程的八个公共基准上对 GLM-4.6 进行了评估。结果显示,GLM-4.6 相比 GLM-4.5 有显著提升,同时在对比 DeepSeek-V3.1-Terminus 和 Claude Sonnet 4 等国内外领先模型时也展现出了竞争优势。
模型推理
GLM-4.5 和 GLM-4.6 都使用相同的推理方法。
你可以查看我们的 github 了解更多详情。
推荐评测参数
在一般评测任务中,推荐使用 采样温度 1.0。
在 代码相关的评测任务(例如 LCB)中,进一步推荐设置:
top_p = 0.95top_k = 40