
VibeVoice:前沿的开源文本转语音模型
VibeVoice是一种新颖的框架,旨在生成表达性强、篇幅长的多发言人对话音频,例如播客内容。它解决了传统文本转语音(TTS)系统面临的重要挑战,特别是在可扩展性、发言人一致性和自然轮换方面。
VibeVoice的一项核心创新是其使用的连续语音标记器(声学和语义),这些标记器以极低的帧率7.5赫兹运行。这些标记器在显著提高处理长序列的计算效率的同时,有效地保留了音频保真度。振动语音采用了一种下一个标记扩散框架,利用大型语言模型(LLM)来理解文本上下文和对话流程,并通过扩散头生成高保真度的声学细节。
该模型可以合成长达90分钟且包含最多4种不同说话人的语音,超过了许多先前模型通常1-2种说话人限制。
➡️ Technical Report: VibeVoice Technical Report
➡️ Project Page: microsoft/VibeVoice
➡️ Code: microsoft/VibeVoice-Code
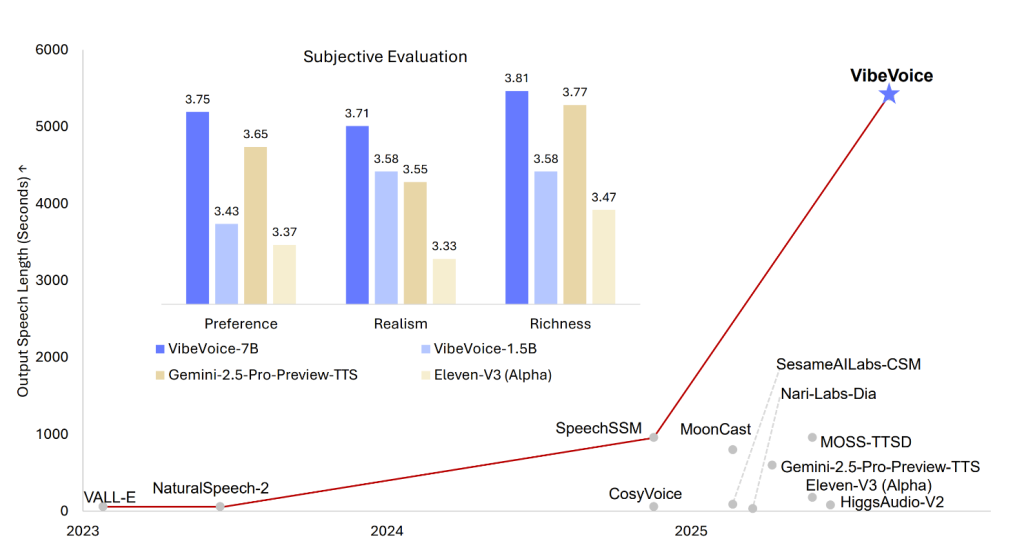
训练细节
基于Transformer的大型语言模型(LLM),结合专用的声学和语义分词器以及基于扩散的解码头。
- LLM: Qwen2.5-1.5B for this release.
- Tokenizers:
- Acoustic Tokenizer: 基于σ-VAE变体(LatentLM中提出),具有镜像对称的编码器-解码器结构,包含7个修改后的Transformer块。从24kHz输入信号实现3200倍下采样。编码器和解码器部分各有约3.4亿参数。
- Semantic Tokenizer: 编码器采用了与声学分词器相同的架构(不含VAE组件)。通过ASR代理任务进行训练。
- Diffusion Head: Lightweight module (4 layers, ~123M parameters) conditioned on LLM hidden states. Predicts acoustic VAE features using a Denoising Diffusion Probabilistic Models (DDPM) process. Uses Classifier-Free Guidance (CFG) and DPM-Solver (and variants) during inference.
- Context Length: Trained with a curriculum increasing up to 65,536 tokens.
- Training Stages:
- Tokenizer Pre-training: Acoustic and Semantic tokenizers are pre-trained separately.
- VibeVoice Training: Pre-trained tokenizers are frozen; only the LLM and diffusion head parameters are trained. A curriculum learning strategy is used for input sequence length (4k -> 16K -> 32K -> 64K). Text tokenizer not explicitly specified, but the LLM (Qwen2.5) typically uses its own. Audio is “tokenized” via the acoustic and semantic tokenizers.
模型参数
| Model | Context Length | Generation Length | Weight |
|---|---|---|---|
| VibeVoice-0.5B-Streaming | – | – | On the way |
| VibeVoice-1.5B | 64K | ~90 min | You are here. |
| VibeVoice-7B-Preview | 32K | ~45 min | HF link |
安装和使用
Please refer to GitHub README
Responsible Usage
Direct intended uses
The VibeVoice model is limited to research purpose use exploring highly realistic audio dialogue generation detailed in the tech report.
Out-of-scope uses
Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by MIT License. Use to generate any text transcript. Furthermore, this release is not intended or licensed for any of the following scenarios:
- Voice impersonation without explicit, recorded consent – cloning a real individual’s voice for satire, advertising, ransom, social‑engineering, or authentication bypass.
- Disinformation or impersonation – creating audio presented as genuine recordings of real people or events.
- Real‑time or low‑latency voice conversion – telephone or video‑conference “live deep‑fake” applications.
- Unsupported language – the model is trained only on English and Chinese data; outputs in other languages are unsupported and may be unintelligible or offensive.
- Generation of background ambience, Foley, or music – VibeVoice is speech‑only and will not produce coherent non‑speech audio.
Risks and limitations
While efforts have been made to optimize it through various techniques, it may still produce outputs that are unexpected, biased, or inaccurate. VibeVoice inherits any biases, errors, or omissions produced by its base model (specifically, Qwen2.5 1.5b in this release). Potential for Deepfakes and Disinformation: High-quality synthetic speech can be misused to create convincing fake audio content for impersonation, fraud, or spreading disinformation. Users must ensure transcripts are reliable, check content accuracy, and avoid using generated content in misleading ways. Users are expected to use the generated content and to deploy the models in a lawful manner, in full compliance with all applicable laws and regulations in the relevant jurisdictions. It is best practice to disclose the use of AI when sharing AI-generated content. English and Chinese only: Transcripts in language other than English or Chinese may result in unexpected audio outputs. Non-Speech Audio: The model focuses solely on speech synthesis and does not handle background noise, music, or other sound effects. Overlapping Speech: The current model does not explicitly model or generate overlapping speech segments in conversations.
Recommendations
We do not recommend using VibeVoice in commercial or real-world applications without further testing and development. This model is intended for research and development purposes only. Please use responsibly.
To mitigate the risks of misuse, we have: Embedded an audible disclaimer (e.g. “This segment was generated by AI”) automatically into every synthesized audio file. Added an imperceptible watermark to generated audio so third parties can verify VibeVoice provenance. Please see contact information at the end of this model card. Logged inference requests (hashed) for abuse pattern detection and publishing aggregated statistics quarterly. Users are responsible for sourcing their datasets legally and ethically. This may include securing appropriate rights and/or anonymizing data prior to use with VibeVoice. Users are reminded to be mindful of data privacy concerns.
Contact
This project was conducted by members of Microsoft Research. We welcome feedback and collaboration from our audience. If you have suggestions, questions, or observe unexpected/offensive behavior in our technology, please contact us at VibeVoice@microsoft.com. If the team receives reports of undesired behavior or identifies issues independently, we will update this repository with appropriate mitigations.
原创文章,转载请注明: 转载自诺德美地科技
本文链接地址: VibeVoice-1.5B