介绍 Qwen3-VL — 迄今为止 Qwen 系列中最强大的视觉语言模型。
这一代产品在各个方面都进行了全面升级:更优秀的文本理解和生成、更深的视觉感知和推理能力、扩展的上下文长度、增强的空间和视频动态理解能力,以及更强的代理交互能力。
提供 Dense 和 MoE 架构,可从边缘到云端进行扩展,并提供 Instruct 和增强推理的 Thinking 版本,以实现灵活、按需部署。
主要增强功能:
- 视觉代理:操作 PC/移动 GUI — 识别元素、理解功能、调用工具、完成任务。
- 视觉编码增强:从图像/视频生成 Draw.io/HTML/CSS/JS。
- 高级空间感知:判断物体位置、视角和遮挡;提供更强的 2D 接地并启用 3D 接地,用于空间推理和具身 AI。
- 长上下文和视频理解:原生 256K 上下文,可扩展至 1M;处理书籍和数小时长的视频,具有完整的回忆和秒级索引。
- 增强的多模态推理:在 STEM/数学方面表现出色 — 因果分析和基于逻辑、证据的答案。
- 升级的视觉识别:更广泛、更高品质的预训练能够“识别一切”——名人、动漫、产品、地标、动植物等。
- 扩展的 OCR:支持 32 种语言(从 19 种增加);在低光、模糊和倾斜情况下表现稳健;更好地处理罕见/古代字符和术语;改进了长文档结构解析。
- 与纯 LLM 相当的文本理解:无缝的文本-视觉融合,实现无损、统一的理解。
模型架构更新:

- 交错 MRoPE:通过强大的位置嵌入,在时间、宽度和高度上进行全面频率分配,增强长时间范围的视频推理。
- DeepStack:融合多层 ViT 特征,捕捉精细细节并锐化图像-文本对齐。
- 文本-时间戳对齐:超越 T-RoPE,实现精确的时间戳基础事件定位,以增强视频时间建模。
这是 Qwen3-VL-235B-A22B-Instruct 的权重仓库。
模型性能
多模态性能
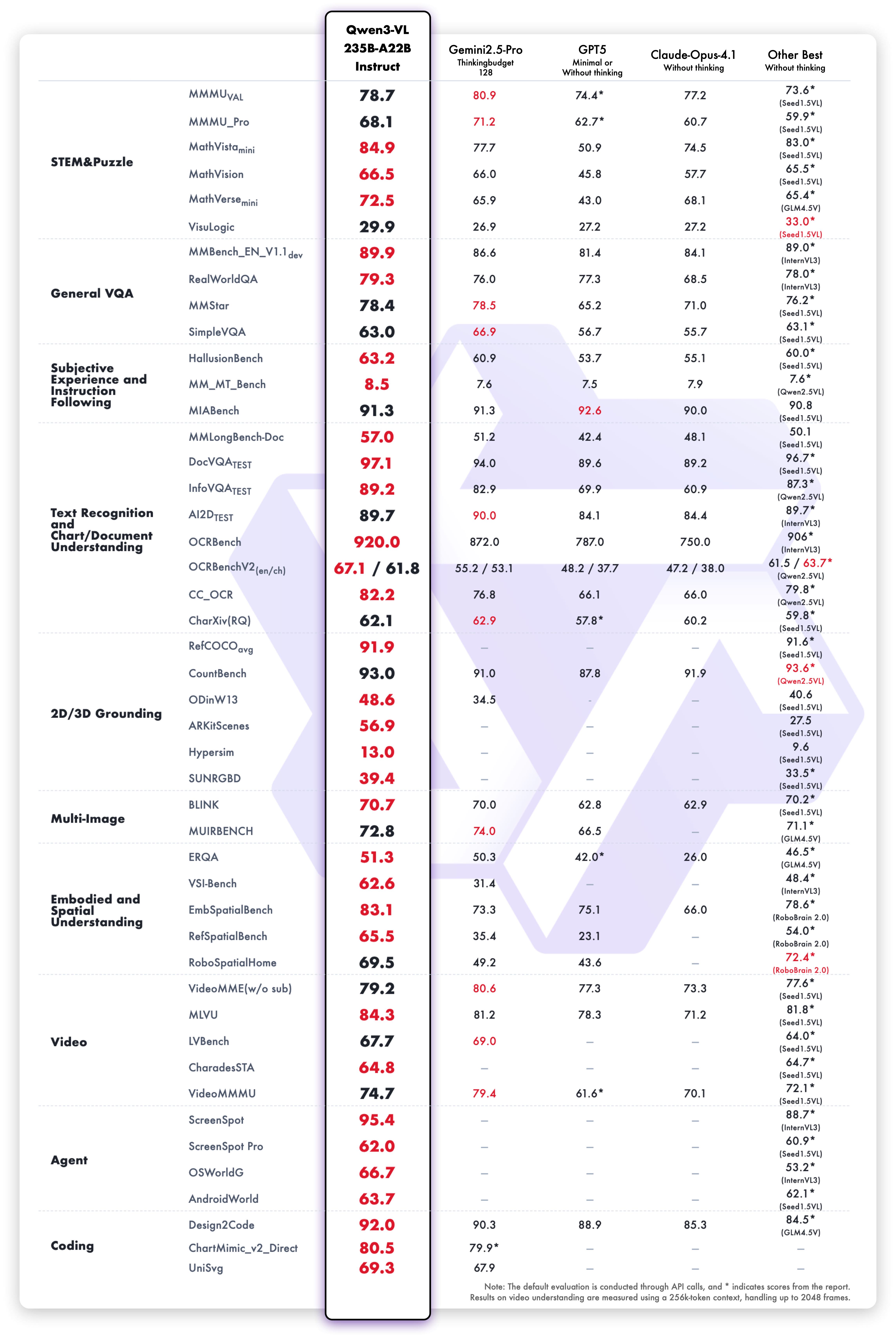
纯文本性能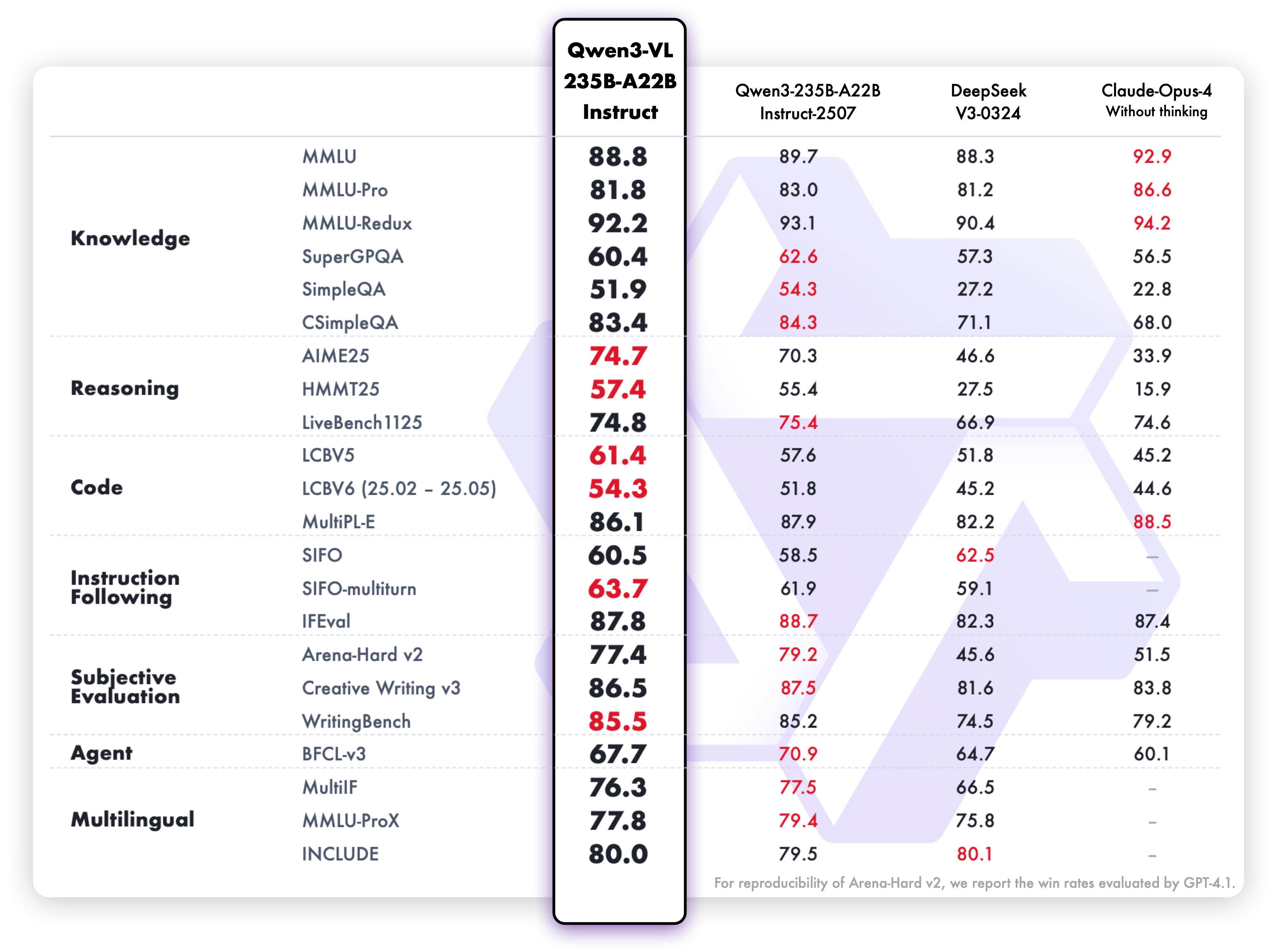
快速开始
下面,我们提供了简单的示例来展示如何使用 🤖 ModelScope 和 🤗 Transformers 来使用 Qwen3-VL。
Qwen3-VL 的代码已在最新的 Hugging Face transformers 中,建议您使用以下命令从源码构建:
pip install git+https://github.com/huggingface/transformers
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
使用 🤗 Transformers 进行聊天
这里我们展示一个代码片段,展示如何使用 transformers 进行聊天:
from modelscope import Qwen3VLMoeForConditionalGeneration, AutoProcessor
# default: Load the model on the available device(s)
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Instruct", dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
# "Qwen/Qwen3-VL-235B-A22B-Instruct",
# dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
引用
如果您觉得我们的工作对您有帮助,请随意引用。
@misc{qwen2.5-VL,
title = {Qwen2.5-VL},
url = {https://qwenlm.github.io/blog/qwen2.5-vl/},
author = {Qwen Team},
month = {January},
year = {2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}