
介绍
今天,我们非常激动地宣布开源 Ling 2.0 —— 一个结合了 SOTA 性能 和 高效率 的基于 MoE 的大型语言模型家族。 首次发布的版本 Ling-mini-2.0 紧凑而强大。它有 16B 总参数,但每个输入令牌仅激活 1.4B(非嵌入 789M)。经过超过 20T 令牌 的高质量数据训练,并通过多阶段监督微调和强化学习增强,Ling-mini-2.0 在复杂推理和指令跟随方面取得了显著改进。尽管只有 1.4B 激活参数,它仍然达到了次 10B 密集 LLM 的顶级水平,甚至与更大的 MoE 模型相匹敌或超越。

强大的通用和专业推理能力
我们在具有挑战性的通用推理任务(如编程(LiveCodeBench, CodeForces)和数学(AIME 2025, HMMT 2025))以及跨多个领域的知识密集型推理任务(MMLU-Pro, Humanity’s Last Exam)上评估了 Ling-mini-2.0。与次 10B 密集模型(例如 Qwen3-4B-instruct-2507, Qwen3-8B-nothinking)和更大规模的 MoE 模型(Ernie-4.5-21B-A3B-PT, GPT-OSS-20B/low)相比,Ling-mini-2.0 展现了出色的总体推理能力。
7 倍等效密集性能杠杆
根据 Ling 缩放定律,Ling 2.0 采用了 1/32 激活比率 的 MoE 架构,并在专家粒度、共享专家比率、注意力比率、无辅助损失 + sigmoid 路由策略、MTP 损失、QK-Norm、半 RoPE 等方面进行了经验优化的设计选择。这使得小激活 MoE 模型能够实现超过 7 倍等效密集性能。换句话说,只有 1.4B 激活参数(非嵌入 789M)的 Ling-mini-2.0 可以提供相当于 7–8B 密集模型的性能。
高速生成:300+ 令牌/秒

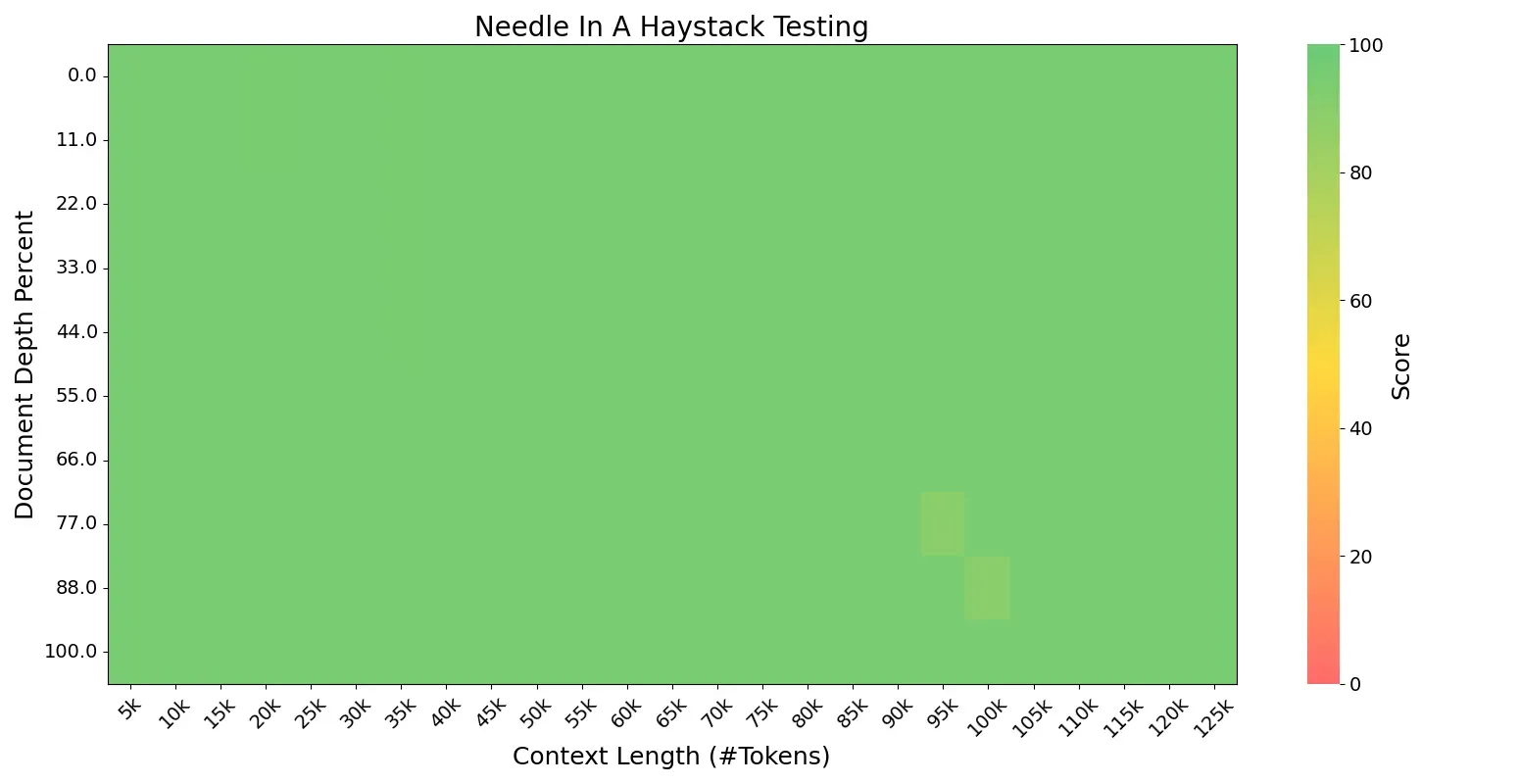
高度稀疏的小激活 MoE 架构还带来了显著的训练和推理效率。在简单的 QA 场景(不超过 2000 个令牌)中,Ling-mini-2.0 在 H20 部署上生成速度为 300+ 令牌/秒 —— 比 8B 密集模型快 超过 2 倍。Ling-mini-2.0 能够使用 YaRN 处理 128K 上下文长度,随着序列长度的增加,相对加速可以达到 超过 7 倍。
开源 FP8 高效训练解决方案
Ling 2.0 全程采用 FP8 混合精度训练。与 BF16 相比,超过 1T 训练令牌的实验显示几乎相同的损失曲线和下游基准性能。为了支持社区在有限计算资源下高效地继续预训练和微调,我们还开源了我们的 FP8 训练解决方案。基于 tile/blockwise FP8 缩放,它进一步引入了 FP8 优化器、FP8 按需转置权重和 FP8 填充路由图,以实现极端内存优化。在 8/16/32 80G GPU 上,与 LLaMA 3.1 8B 和 Qwen3 8B 相比,Ling-mini-2.0 在启用 MTP 时实现了 30–60% 的吞吐量提升,在禁用 MTP 时实现了 90–120% 的吞吐量提升。
更加开放的开源策略
我们认为 Ling-mini-2.0 是 MoE 研究的理想起点。这是首次在这一规模上整合了 1/32 稀疏性、MTP 层和 FP8 训练 —— 实现了强大的有效性和高效的训练/推理性能,使其成为小型 LLM 细分市场的首选。 为了进一步促进社区研究,除了发布后训练版本外,我们还开源了 五个预训练检查点:预微调的 Ling-mini-2.0-base 以及四个分别在 5T、10T、15T 和 20T 令牌上训练的基础模型,从而支持更深入的研究和更广泛的应用。
模型下载
您可以下载以下表格,查看 Ling-mini-2.0 模型(16.26B 总参数中的 1.43B 激活参数)的各种阶段。如果您位于中国大陆,我们还在 ModelScope.cn 上提供了该模型,以加快下载过程。
| 模型 | 上下文长度 | 下载 |
|---|---|---|
| Ling-mini-base-2.0 | 32K -> 128K (YaRN) | 🤗 HuggingFace 🤖 ModelScope |
| Ling-mini-base-2.0-5T | 4K | 🤗 HuggingFace 🤖 ModelScope |
| Ling-mini-base-2.0-10T | 4K | 🤗 HuggingFace 🤖 ModelScope |
| Ling-mini-base-2.0-15T | 4K | 🤗 HuggingFace 🤖 ModelScope |
| Ling-mini-base-2.0-20T | 4K | 🤗 HuggingFace 🤖 ModelScope |
| Ling-mini-2.0 | 32K -> 128K (YaRN) | 🤗 HuggingFace 🤖 ModelScope |
注意:如果您对以前的版本感兴趣,请访问Huggingface或ModelScope中的过去模型集合。
快速开始
转换为safetensors格式
safetensors格式的模型可以从HuggingFace或ModelScope下载。 如果您想训练您的模型并评估它,您可以从训练产生的dcp进行转换。
python tools/convert_dcp_to_safe_tensors.py --checkpoint-path ${DCP_PATH} --target-path ${SAFETENSORS_PATH}
目前支持BF16和FP8格式,您可以使用转换参数来处理:
--force-bf16用于BF16格式。--force-fp8用于FP8格式。
🤗 Hugging Face Transformers
以下代码片段展示了如何使用transformers库与聊天模型:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "inclusionAI/Ling-mini-2.0"
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language models."
messages = [
{"role": "system", "content": "You are Ling, an assistant created by inclusionAI"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt", return_token_type_ids=False).to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
🤖 ModelScope
如果您在中国大陆,我们强烈建议您使用来自🤖 ModelScope的模型。
部署
vLLM
vLLM支持离线批量推理或启动一个兼容OpenAI的API服务进行在线推理。
环境准备
由于拉取请求(PR)尚未提交到vLLM社区,请按照以下步骤准备环境:
git clone -b v0.10.0 https://github.com/vllm-project/vllm.git
cd vllm
git apply Ling-V2/inference/vllm/bailing_moe_v2.patch
pip install -e .
离线推理:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
tokenizer = AutoTokenizer.from_pretrained("inclusionAI/Ling-mini-2.0")
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=16384)
llm = LLM(model="inclusionAI/Ling-mini-2.0", dtype='bfloat16')
prompt = "Give me a short introduction to large language models."
messages = [
{"role": "system", "content": "You are Ling, an assistant created by inclusionAI"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
outputs = llm.generate([text], sampling_params)
在线推理:
VLLM_USE_MODELSCOPE=true vllm serve inclusionAI/Ling-mini-2.0 \
--tensor-parallel-size 2 \
--pipeline-parallel-size 1 \
--use-v2-block-manager \
--gpu-memory-utilization 0.90
要在vLLM中使用YaRN处理长上下文,我们需要遵循以下两个步骤:
- 在模型的
config.json文件中添加一个rope_scaling字段,例如:
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
- 启动vLLM服务时使用额外参数
--max-model-len指定所需的最长上下文长度。
有关详细指南,请参阅vLLM的说明。
SGLang
环境准备
我们将稍后将我们的模型提交给SGLang官方发布,现在我们可以按照以下步骤准备环境:
pip3 install sglang==0.5.2rc0 sgl-kernel==0.3.7.post1
您也可以使用Docker镜像:
docker pull lmsysorg/sglang:v0.5.2rc0-cu126
然后您应该应用补丁到sglang安装:
# patch command is needed, run `yum install -y patch` if needed
patch -d `python -c 'import sglang;import os; print(os.path.dirname(sglang.__file__))'` -p3 < inference/sglang/bailing_moe_v2.patch
运行推理
SGLang现在支持BF16和FP8模型,这取决于${MODEL_PATH}中模型的数据类型。它们都共享以下相同的命令:
- 启动服务器:
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server \
--model-path $MODLE_PATH \
--host 0.0.0.0 --port $PORT \
--trust-remote-code \
--attention-backend fa3
基础模型支持MTP,但聊天模型还不支持。您可以在启动命令中添加参数--speculative-algorithm NEXTN。
- 客户端:
curl -s http://localhost:${PORT}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "auto", "messages": [{"role": "user", "content": "What is the capital of France?"}]}'
"""
更多用法请参见这里
训练
我们还提供了一个完整的高效训练框架,涵盖了预训练和微调。基于此框架,可以继续在Ling-mini-2.0检查点上进行训练。通过我们的训练框架,Ling-mini-2.0模型的训练吞吐量显著优于现有的密集型8B模型(Qwen3-8B, Llama3-8B)。
预训练
预训练演示以继续预训练Ling模型。
性能基准
下表显示了几种模型在8、16和32个80G GPU上的预训练性能,单位为每秒标记数。与基线相比,Ling-mini-2.0实现了显著更高的训练效率,使得使用我们的演示脚本继续预训练更加容易且成本更低。
| 模型 | 8 x 80G GPU (GBS=128) | 16 x 80G GPU (GBS=256) | 32 x 80G GPU (GBS=512) |
|---|---|---|---|
| LLaMA 3.1 8B (基准) | 81222 | 161319 | 321403 |
| Qwen3 8B | 55775 (-31.33%) | 109799 (-31.94%) | 219943 (-31.57%) |
| Ling-mini-2.0 | 109532 (+34.86%) | 221585 (+37.36%) | 448726 (+39.61%) |
| Ling-mini-2.0 w/o MTP | 128298 (+57.96%) | 307264 (+90.47%) | 611466 (+90.25%) |
微调
我们建议您使用 Llama-Factory 来 微调 Ling。除此之外,您还可以使用 Megatron 进行微调。
许可证
此代码仓库采用 MIT 许可证。
引用
如果您觉得我们的工作对您有帮助,请随意引用我们。
原创文章,转载请注明: 转载自诺德美地科技
本文链接地址: Ling-mini-2.0