概览
简介
Qwen3-Omni 是一个原生端到端多语言全模态基础模型。它处理文本、图像、音频和视频,并以文本和自然语音形式提供实时流式响应。我们引入了多项架构升级,以提高性能和效率。主要特点:
- 跨模态的最先进技术:早期以文本为主的预训练和混合多模态训练提供了原生多模态支持。在实现强大的音频和音视频结果的同时,单模态文本和图像性能没有退化。在36个音频/视频基准测试中的22个上达到SOTA,在36个中的32个上达到开源SOTA;ASR、音频理解和语音对话性能与Gemini 2.5 Pro相当。
- 多语言:支持119种文本语言,19种语音输入语言和10种语音输出语言。
- 语音输入:英语、中文、韩语、日语、德语、俄语、意大利语、法语、西班牙语、葡萄牙语、马来语、荷兰语、印度尼西亚语、土耳其语、越南语、粤语、阿拉伯语、乌尔都语。
- 语音输出:英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语。
- 新颖的架构:基于MoE的思考者-说话者设计,通过AuT预训练获得强大的通用表示,加上多码本设计,将延迟降至最低。
- 实时音频/视频交互:低延迟流媒体,具有自然的轮流发言和即时文本或语音响应。
- 灵活控制:通过系统提示自定义行为,实现细粒度控制和轻松适应。
- 详细的音频字幕生成器:Qwen3-Omni-30B-A3B-Captioner现已开源:这是一个通用的、高度详细的、低幻觉的音频字幕生成模型,填补了开源社区的一个关键空白。
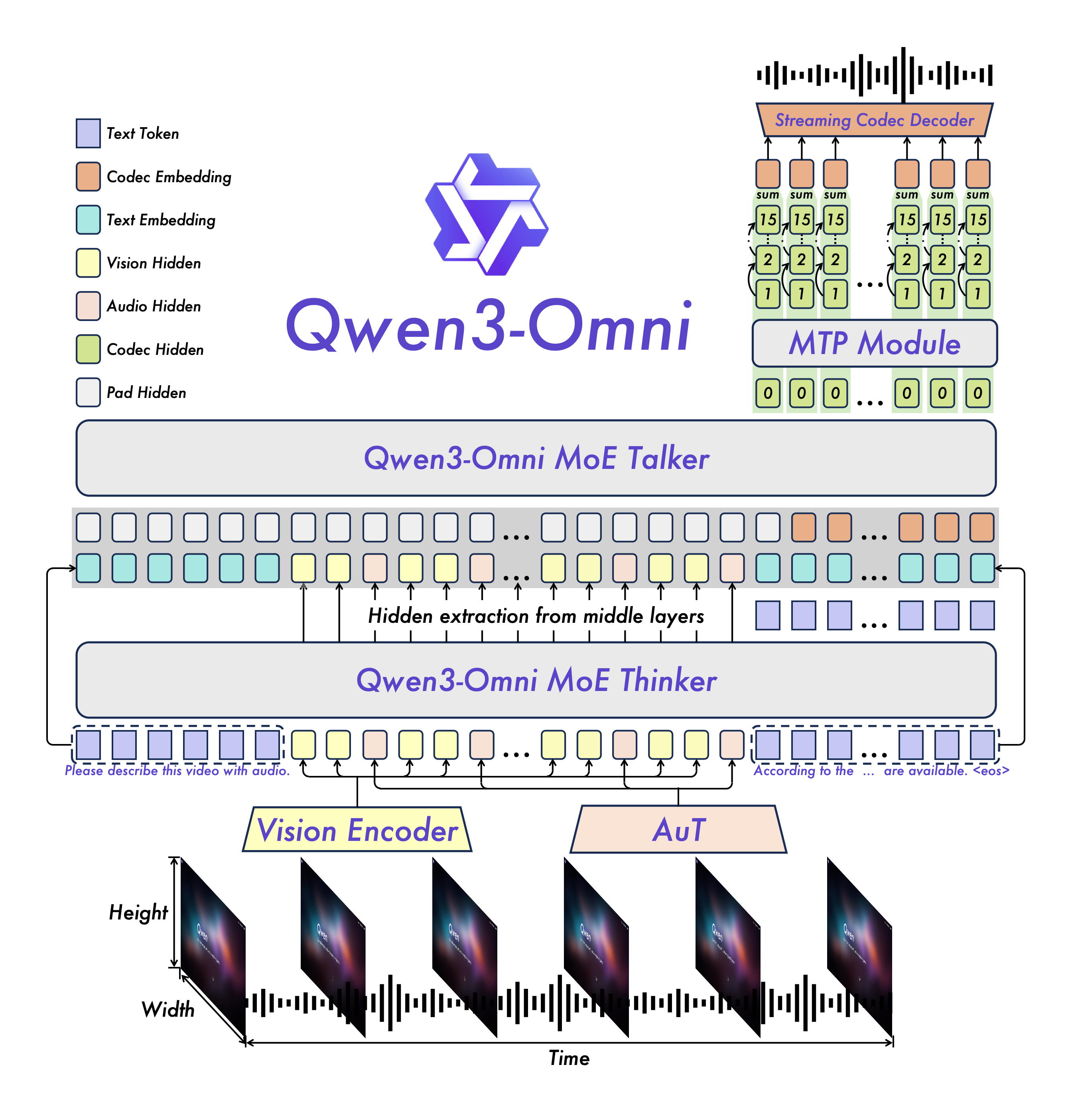
模型架构
使用案例指南
Qwen3-Omni 支持广泛的多模态应用场景,涵盖涉及音频、图像、视频和视听模态的各种领域任务。以下是几个展示 Qwen3-Omni 使用案例的手册,这些手册包括我们的实际执行日志。您可以先按照快速入门指南下载模型并安装必要的推理环境依赖项,然后在本地运行和实验—尝试修改提示或切换模型类型,享受探索 Qwen3-Omni 的能力!
请提供需要翻译的 markdown 内容。
| Category | Cookbook | Description | Open |
|---|---|---|---|
| Audio | Speech Recognition | Speech recognition, supporting multiple languages and long audio. | |
| Speech Translation | Speech-to-Text / Speech-to-Speech translation. | ||
| Music Analysis | Detailed analysis and appreciation of any music, including style, genre, rhythm, etc. | ||
| Sound Analysis | Description and analysis of various sound effects and audio signals. | ||
| Audio Caption | Audio captioning, detailed description of any audio input. | ||
| Mixed Audio Analysis | Analysis of mixed audio content, such as speech, music, and environmental sounds. | ||
| Visual | OCR | OCR for complex images. | |
| Object Grounding | Target detection and grounding. | ||
| Image Question | Answering arbitrary questions about any image. | ||
| Image Math | Solving complex mathematical problems in images, highlighting the capabilities of the Thinking model. | ||
| Video Description | Detailed description of video content. | ||
| Video Navigation | Generating navigation commands from first-person motion videos. | ||
| Video Scene Transition | Analysis of scene transitions in videos. | ||
| Audio-Visual | Audio Visual Question | Answering arbitrary questions in audio-visual scenarios, demonstrating the model’s ability to model temporal alignment between audio and video. | |
| Audio Visual Interaction | Interactive communication with the model using audio-visual inputs, including task specification via audio. | ||
| Audio Visual Dialogue | Conversational interaction with the model using audio-visual inputs, showcasing its capabilities in casual chat and assistant-like behavior. | ||
| Agent | Audio Function Call | Using audio input to perform function calls, enabling agent-like behaviors. | |
| Downstream Task Fine-tuning | Omni Captioner | Introduction and capability demonstration of Qwen3-Omni-30B-A3B-Captioner, a downstream fine-tuned model based on Qwen3-Omni-30B-A3B-Instruct, illustrating the strong generalization ability of the Qwen3-Omni foundation model. |
请提供需要翻译的markdown内容。
快速入门
模型描述和下载
以下是所有 Qwen3-Omni 模型的描述。请选择并下载适合您需求的模型。
| 模型名称 | 描述 |
|---|---|
| Qwen3-Omni-30B-A3B-Instruct | Qwen3-Omni-30B-A3B 的指令模型,包含思考者和说话者组件,支持音频、视频和文本输入,输出音频和文本。更多信息请阅读 Qwen3-Omni 技术报告。 |
| Qwen3-Omni-30B-A3B-Thinking | Qwen3-Omni-30B-A3B 的思考模型,包含思考者组件,具备链式思维推理能力,支持音频、视频和文本输入,输出文本。更多信息请阅读 Qwen3-Omni 技术报告。 |
| Qwen3-Omni-30B-A3B-Captioner | 从 Qwen3-Omni-30B-A3B-Instruct 微调而来的下游音频细粒度字幕模型,为任意音频输入生成详细且低幻觉的字幕。它包含思考者组件,支持音频输入和文本输出。更多信息可以参考该模型的 cookbook。 |
在 Hugging Face Transformers 或 vLLM 中加载时,会根据模型名称自动下载模型权重。然而,如果您的运行环境不便于在执行过程中下载权重,您可以参考以下命令手动将模型权重下载到本地目录:
# Download through ModelScope (recommended for users in Mainland China)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni-30B-A3B-Instruct
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Thinking --local_dir ./Qwen3-Omni-30B-A3B-Thinking
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Captioner --local_dir ./Qwen3-Omni-30B-A3B-Captioner
# Download through Hugging Face
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Instruct --local-dir ./Qwen3-Omni-30B-A3B-Instruct
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Thinking --local-dir ./Qwen3-Omni-30B-A3B-Thinking
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Captioner --local-dir ./Qwen3-Omni-30B-A3B-Captioner
Transformers 使用方法
安装
Qwen3-Omni 的 Hugging Face Transformers 代码已成功合并,但 PyPI 包尚未发布。因此,您需要使用以下命令从源码安装。我们强烈建议您创建一个新的 Python 环境以避免环境运行时问题。
# If you already have transformers installed, please uninstall it first, or create a new Python environment
# pip uninstall transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
我们提供了一个工具包,帮助您更方便地处理各种类型的音频和视觉输入,提供类似 API 的体验。这包括对 base64、URL 以及交错音频、图像和视频的支持。您可以使用以下命令进行安装,并确保您的系统已安装 ffmpeg:
pip install qwen-omni-utils -U
此外,我们建议在使用 Hugging Face Transformers 运行时使用 FlashAttention 2 以减少 GPU 内存使用。但是,如果您主要使用 vLLM 进行推理,则无需此安装,因为 vLLM 默认包含 FlashAttention 2。
pip install -U flash-attn --no-build-isolation
同时,您的硬件应与 FlashAttention 2 兼容。更多详情请参阅 FlashAttention 仓库 的官方文档。FlashAttention 2 仅在模型以 torch.float16 或 torch.bfloat16 加载时才能使用。
代码片段
以下是一个代码片段,展示如何使用 transformers 和 qwen_omni_utils 来使用 Qwen3-Omni:
import soundfile as sf
from modelscope import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Thinking"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"},
{"type": "audio", "audio": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"},
{"type": "text", "text": "What can you see and hear? Answer in one short sentence."}
],
},
]
# Set whether to use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs,
speaker="Ethan",
thinker_return_dict_in_generate=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids.sequences[:, inputs["input_ids"].shape[1] :],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
print(text)
if audio is not None:
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
这里有一些更高级的使用示例。您可以展开下面的部分来了解更多。批量推理是否使用音频输出
vLLM 使用方法
安装
我们强烈建议使用 vLLM 进行 Qwen3-Omni 系列模型的推理和部署。由于我们的代码目前处于拉取请求阶段,并且 指令模型的音频输出推理支持将在不久的将来发布,您可以按照以下命令从源码安装 vLLM。请注意,我们建议您创建一个新的 Python 环境以避免运行时环境冲突和不兼容。有关从源码编译 vLLM 的更多详细信息,请参阅 vLLM 官方文档。
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm
pip install -r requirements/build.txt
pip install -r requirements/cuda.txt
export VLLM_PRECOMPILED_WHEEL_LOCATION=https://wheels.vllm.ai/a5dd03c1ebc5e4f56f3c9d3dc0436e9c582c978f/vllm-0.9.2-cp38-abi3-manylinux1_x86_64.whl
VLLM_USE_PRECOMPILED=1 pip install -e . -v --no-build-isolation
# If you meet an "Undefined symbol" error while using VLLM_USE_PRECOMPILED=1, please use "pip install -e . -v" to build from source.
# Install the Transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
pip install qwen-omni-utils -U
pip install -U flash-attn --no-build-isolation
推理
您可以使用以下代码进行 vLLM 推理。limit_mm_per_prompt 参数指定了每条消息允许的每种模态数据的最大数量。由于 vLLM 需要预分配 GPU 内存,较大的值将需要更多的 GPU 内存;如果出现 OOM 问题,请尝试减小此值。设置 tensor_parallel_size 大于一则可以启用多 GPU 并行推理,提高并发性和吞吐量。此外,max_num_seqs 表示 vLLM 在每次推理步骤中并行处理的序列数量。较大的值需要更多的 GPU 内存,但可以实现更高的批处理推理速度。更多详情,请参阅 vLLM 官方文档。下面是一个如何使用 vLLM 运行 Qwen3-Omni 的简单示例:
import os
import torch
from vllm import LLM, SamplingParams
from modelscope import Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
if __name__ == '__main__':
# vLLM engine v1 not supported yet
os.environ['VLLM_USE_V1'] = '0'
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Thinking"
llm = LLM(
model=MODEL_PATH, trust_remote_code=True, gpu_memory_utilization=0.95,
tensor_parallel_size=torch.cuda.device_count(),
limit_mm_per_prompt={'image': 3, 'video': 3, 'audio': 3},
max_num_seqs=8,
max_model_len=32768,
seed=1234,
)
sampling_params = SamplingParams(
temperature=0.6,
top_p=0.95,
top_k=20,
max_tokens=16384,
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/draw.mp4"}
],
}
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
inputs = {
'prompt': text,
'multi_modal_data': {},
"mm_processor_kwargs": {
"use_audio_in_video": True,
},
}
if images is not None:
inputs['multi_modal_data']['image'] = images
if videos is not None:
inputs['multi_modal_data']['video'] = videos
if audios is not None:
inputs['multi_modal_data']['audio'] = audios
outputs = llm.generate([inputs], sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
这里还有一些更高级的使用示例。您可以展开下面的部分以了解更多信息。批量推理vLLM Serve 使用
使用技巧(推荐阅读)
最低 GPU 内存要求
| 模型 | 精度 | 15秒视频 | 30秒视频 | 60秒视频 | 120秒视频 |
|---|---|---|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct | BF16 | 78.85 GB | 88.52 GB | 107.74 GB | 144.81 GB |
| Qwen3-Omni-30B-A3B-Thinking | BF16 | 68.74 GB | 77.79 GB | 95.76 GB | 131.65 GB |
注意:上表展示了使用 transformers 和 BF16 精度进行推理时的理论最低内存需求,测试条件为 attn_implementation="flash_attention_2"。Instruct 模型包括 thinker 和 talker 组件,而 Thinking 模型仅包括 thinker 部分。
音视频交互提示
当使用 Qwen3-Omni 进行音视频多模态交互时,输入由一个视频及其对应的音频组成(音频作为查询),我们建议使用 以下系统提示。这种设置有助于模型保持高推理能力,同时更好地承担如智能助手等交互角色。此外,thinker 生成的文本将更具可读性,具有自然、对话式的语气,并且没有难以发音的复杂格式,从而使得 talker 生成的音频输出更加稳定流畅。您可以根据需要自定义系统提示中的 user_system_prompt 字段,以包含角色设置或其他特定角色描述。
user_system_prompt = "You are Qwen-Omni, a smart voice assistant created by Alibaba Qwen."
message = {
"role": "system",
"content": [
{"type": "text", "text": f"{user_system_prompt} You are a virtual voice assistant with no gender or age.\nYou are communicating with the user.\nIn user messages, “I/me/my/we/our” refer to the user and “you/your” refer to the assistant. In your replies, address the user as “you/your” and yourself as “I/me/my”; never mirror the user’s pronouns—always shift perspective. Keep original pronouns only in direct quotes; if a reference is unclear, ask a brief clarifying question.\nInteract with users using short(no more than 50 words), brief, straightforward language, maintaining a natural tone.\nNever use formal phrasing, mechanical expressions, bullet points, overly structured language. \nYour output must consist only of the spoken content you want the user to hear. \nDo not include any descriptions of actions, emotions, sounds, or voice changes. \nDo not use asterisks, brackets, parentheses, or any other symbols to indicate tone or actions. \nYou must answer users' audio or text questions, do not directly describe the video content. \nYou should communicate in the same language strictly as the user unless they request otherwise.\nWhen you are uncertain (e.g., you can't see/hear clearly, don't understand, or the user makes a comment rather than asking a question), use appropriate questions to guide the user to continue the conversation.\nKeep replies concise and conversational, as if talking face-to-face."}
]
}
思维模型的最佳实践
Qwen3-Omni-30B-A3B-Thinking 模型主要用于理解和与多模态输入(包括文本、音频、图像和视频)进行交互。为了获得最佳性能,我们建议用户在每轮对话中除了多模态输入外,还包含明确的文本指令或任务描述。这有助于澄清意图,并显著增强模型利用其推理能力的能力。例如:
messages = [
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "image", "image": "/path/to/image.png"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "text", "text": "Analyze this audio, image, and video together."},
],
}
]
在视频中使用音频
在多模态交互中,用户提供的视频通常会附带音频(例如口头提问或视频中的声音)。这些信息有助于模型提供更好的交互体验。我们提供了以下选项供用户决定是否使用视频中的音频。
# In data preprocessing
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
# For Transformers
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt",
padding=True, use_audio_in_video=True)
text_ids, audio = model.generate(..., use_audio_in_video=True)
# For vLLM
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
inputs = {
'prompt': text,
'multi_modal_data': {},
"mm_processor_kwargs": {
"use_audio_in_video": True,
},
}
值得注意的是,在多轮对话过程中,use_audio_in_video 参数必须在这些步骤中保持一致;否则可能会出现意外结果。
评估
Qwen3-Omni 的性能
Qwen3-Omni 在文本和视觉模态上保持了最先进的性能,相对于相同大小的单模型 Qwen 对手没有退化。在 36 个音频和视听基准测试中,它在 32 个上实现了开源 SOTA,并在 22 个上设定了 SOTA,超过了 Gemini 2.5 Pro 和 GPT-4o 等强大的闭源系统。文本 -> 文本音频 -> 文本视觉 -> 文本音视频到文本零样本语音生成多语言语音生成跨语言语音生成
评估设置
- 解码策略:对于所有评估基准中的Qwen3-Omni系列,
Instruct模型在生成过程中使用贪婪解码而不进行采样。对于Thinking模型,解码参数应从检查点中的generation_config.json文件中获取。 - 基准特定格式:对于大多数评估基准,它们自带ChatML格式以嵌入问题或提示。需要注意的是,在评估期间所有视频数据均设置为
fps=2。 - 默认提示:对于某些不包含提示的任务,我们使用以下提示设置:
| 任务类型 | 提示 |
|---|---|
| 中文自动语音识别 (ASR) | 请将这段中文语音转换为纯文本。 |
| 其他语言的自动语音识别 (ASR) | 将<语言>音频转录为文本。 |
| 语音到文本翻译 (S2TT) | 听取提供的<源语言>语音并生成<目标语言>文本的翻译。 |
| 歌词识别 | 将歌词转录为文本,不带任何标点符号,用换行符分隔各行,并仅输出歌词,不附加其他解释。 |
- 系统提示:任何评估基准都不应设置
系统提示。 - 输入序列:问题或提示应作为用户文本输入。除非基准另有规定,否则文本应在多模态数据之后出现。例如:
messages = [
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "image", "image": "/path/to/image.png"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "text", "text": "Describe the audio, image and video."},
],
},
]
原创文章,转载请注明: 转载自诺德美地科技
本文链接地址: Qwen3-Omni